How To a Code HTTP Client Using Socket - Python
In this tutorial we'll be writing a very simple HTTP client.
HTTP (or Hyper Text Transfer Protocol) is a text-based client-server protocol that runs over TCP.
Plain HTTP runs over TCP
port 80.
It should be noted that plain HTTP is mostly deprecated for security reasons.
Today, sites should use HTTPS, the secure version of HTTP.
HTTPS secures HTTP by merely running
the HTTP protocol through a Transport Layer Security (TLS) layer
In order to code a http client we need to have a basic understanding
of the protocol specification.

What You Should Know
It is suggested that you've the basic knowledge of the socket module
HTTP Request type
- GET: Is used requesting a document from the server.
- POST: Is used sending data from the client to the server.
- HEAD: It's just like GET request but the response is just response header instead of receiving the both response header and response body.
- PUT: Is used to send a document to the web server.
- DELETE: Is used to request that the web server should delete a document or resource.
- TRACE: Is used to request diagnostic information from web proxies.
- CONNECT: Is sometimes used to initiate an HTTP connection through a proxy server.
- OPTIONS: Is used to ask which HTTP request types are supported by the server for a given resource.
HTTP Request Format
If you open your web browser and navigate to http://www.example.com/page1.htm, your browser will need to send an HTTP request to the web server at www.example.com. That HTTP request may look like this:
GET /page1.htm HTTP/1.1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
Host: example.com
Connection: close
From the above request example, the GET means we want to get a document from the server,
and the document path on the server is /page1.html.
and the HTTP/1.1 is protocol and the version(1.1).
The User-Agent header is the name of the software requesting the page.
The Host header is the name of the host we're requesting the page from.
The Connection header tells the server what to do after finishing request,
the value of this field can be Keep-Alive or close which means
to keep the connection alive or close the connection after sending response respectively.
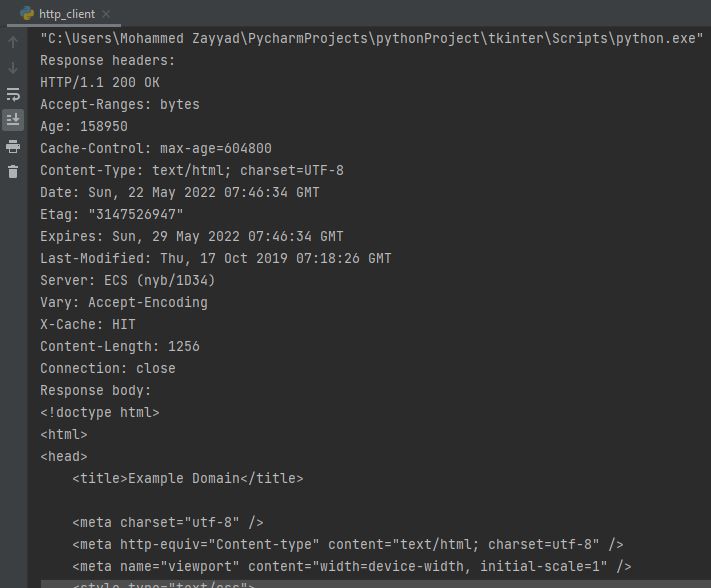
HTTP Response Format
Like the HTTP request, the HTTP response also consists of a header part and a body part.
Also similar to the HTTP request, the body part is optional.
Most HTTP responses do have
a body part, though.
The server at www.example.com could respond to our HTTP request with the following
reply:
HTTP/1.1 200 OK
Cache-Control: max-age=604800
Content-Type: text/html; charset=UTF-8
Date: Sun, 22 May 2022 16:46:09 GMT
Etag: "1541025663+gzip"
Expires: Sun, 29 May 2022 16:46:09 GMT
Last-Modified: Fri, 09 Aug 2013 23:54:35 GMT
Server: ECS (ord/5730)
Vary: Accept-Encoding
X-Cache: HIT
Content-Length: 1270
<!doctype html>
<html>
<head>
<title>Example Domain</title>
...
The 200 from the above response is the status code which means
everything is OK or request successful.
The Content-Length is the size of the document we're receiving.
In HTTP we use CRLF('\r\n') to indicate the end of each header, we
use double CRLF('\r\n\r\n') to indicate the end of the request headers
or response headers.
Now that we have some basics of how this protocol works let's make
a HTTP request from our python program.
First we'll import the socket module and define a class
class HTTPClient:
def __init__(self, url):
self.url = url
self.buffer_size = 4096
self.__parse_url__()
In the constructor, the user needs to pass in the URL for this connection.
and we define a buffer_size which is the maximum size of data to be received,
and then we called self.__parse_url__() to break-down the url, the method
defination is next
.
The next function will be used to break-down the URL into:
- Protocol
- Hostname
- Port
- Path
- Query string
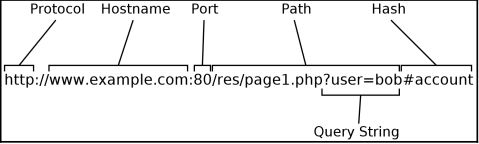
def __parse_url__(self):
# Get the protocol,e.g http, https etc
# If no protocol specified we raised an exception
url = self.url
try:
self.protocol, url = url.split('://')
except ValueError:
raise Exception('Invalid URL')
# we make sure that the protocol is http
# otherwise we raise an exception saying protocol is not supported
if self.protocol != 'http':
raise Exception(f'Protocol not supported: {self.protocol}')
# Get the hostname and port, example www.google.com:80
hostname_port = url.split('/')[0]
# Python will raises a ValueError if there's no enough
# values to unpack, which means there's no port number
# so we'll just default to 80
try:
self.hostname, self.port = hostname_port.split(':')
except ValueError:
self.hostname = hostname_port
self.port = 80
# get the path
try:
self.path = url.split('/')[1]
self.path = '/' + self.path
except IndexError:
self.path = '/'
# remove any query string from our path
if '?q=' in self.path:
self.path = self.path.split('?q=')[0]
# get the query string (if available)
try:
self.query = url.split('?q=')[1]
except IndexError:
self.query = ''
# remove the '#' from the query string if it contains any
if '#' in self.query:
self.query = self.query.split('#')[0]
Next we'll define another method for establishing connection to the server.
def __connect__(self):
# resolve hostname to ip
ip = socket.gethostbyname(self.hostname)
# we create a IPv4/IPv6 dual stack socket
# for connection
self.socket = socket.create_connection((ip, self.port), timeout=5)
Next we'll define our last function for sending and receiving request and response respectively.
This function will return the response from the server.
def perform_request(self):
# first we connect to the server
self.__connect__()
# we contruct our request header
request_headers = \
f"GET /{self.path}{self.query} HTTP/1.1\r\n" \
f"Host: {self.hostname}:{self.port}\r\n" \
"User-Agent: Python http/0.1\r\n" \
"Connection: close\r\n" \
"\r\n"
# send the request headers
self.socket.send(request_headers.encode())
self.response = ''
# receive response
while True:
data = self.socket.recv(self.buffer_size)
if len(data) == 0:
# finished receiving data
break
self.response = self.response + data.decode()
# return the response
return self.response
Full Source Code
class HTTPClient:
def __init__(self, url):
self.url = url
self.buffer_size = 4096
self.__parse_url__()
# function for parsing the URL
def __parse_url__(self):
# Get the protocol,e.g http, https etc
# If no protocol specified we raised an exception
url = self.url
try:
self.protocol, url = url.split('://')
except ValueError:
raise Exception('Invalid URL')
# we make sure that the protocol is http
# otherwise we raise an exception ssaying protocol is not supported
if self.protocol != 'http':
raise Exception(f'Protocol not supported: {self.protocol}')
# Get the hostname and port, example www.google.com:80
hostname_port = url.split('/')[0]
# Python will raises a ValueError if there's no enough
# values to unpack, which means there's no port number
# so we'll just default to 80
try:
self.hostname, self.port = hostname_port.split(':')
except ValueError:
self.hostname = hostname_port
self.port = 80
# get the path
try:
self.path = url.split('/')[1]
self.path = '/' + self.path
except IndexError:
self.path = '/'
# remove any query string from our path
if '?q=' in self.path:
self.path = self.path.split('?q=')[0]
# get the query string (if available)
try:
self.query = url.split('?q=')[1]
except IndexError:
self.query = ''
# remove the '#' from the query string if it contains any
if '#' in self.query:
self.query = self.query.split('#')[0]
# function for connecting to the server
def __connect__(self):
# resolve hostname to ip
ip = socket.gethostbyname(self.hostname)
# we create a IPv4, IPv6 dual stack socket
# for connection
self.socket = socket.create_connection((ip, self.port), timeout=5)
# function for sending a HTTP get request
def perform_request(self):
# first we connect to the server
self.__connect__()
# we contruct our request header
request_headers = \
f"GET /{self.path}{self.query} HTTP/1.1\r\n" \
f"Host: {self.hostname}:{self.port}\r\n" \
"User-Agent: Python http/0.1\r\n" \
"Connection: close\r\n" \
"\r\n"
# send the request headers
self.socket.send(request_headers.encode())
self.response = ''
# receive response
while True:
data = self.socket.recv(self.buffer_size)
if len(data) == 0:
# finished receiving data
break
self.response = self.response + data.decode()
# return the response
return self.response
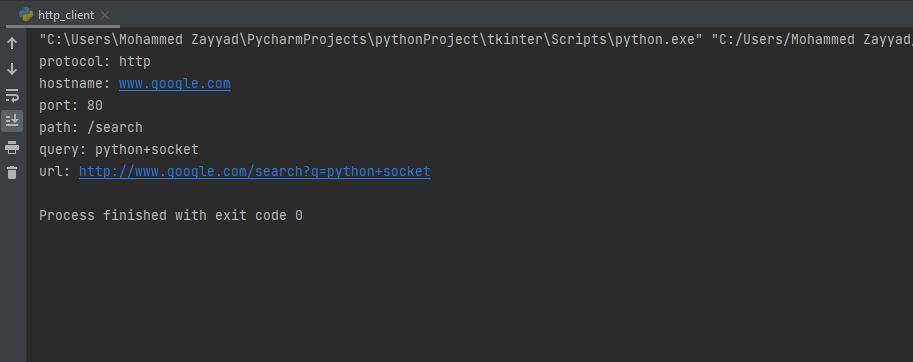
We can use our class to parse URL as a bonus:
print(f"protocol: {http_client.protocol}")
print(f"hostname: {http_client.hostname}")
print(f"port: {http_client.port}")
print(f"path: {http_client.path}")
print(f"query: {http_client.query}")
print(f"url: {http_client.url}")
Here is what I got after running the code:
It's finally time to make some request!
response = http_client.perform_request()
headers_body = response.split("\r\n\r\n")
print(f"Response headers:\n{headers_body[0]}")
print(f"Response body:\n{headers_body[1]}")
After performing the request, This is what I get.